3과목 : 01 R기초
A.그래프
Boxplot 해석
1. 중위수는 상자의 선으로 표시되며 데이터 중심의 일반적인 측도로, 관측치의 절반은 이 값보다 작거나 같고 절반은 이 값보다 크거나 같다
2. 사분위 간 범위 상자는 데이터의 중간 50%를 나타내며, 제1사분위수와 제3사분위수 값을 거리를 보여준다
3. 수염은 상자의 양쪽에서 연결되며, 특이치를 제외하고 데이터 값의 하위 25%와 상위 25%를 범위를 나타낸다
4. 상자박스는 그룹간 분포 차이를 비교할 수 있으며, 그 차이는 통계적으로 유의미함을 보일 수는 없다
5. 상자그림은 그룹 간 분포 차이를 비교할 수 있다
6. 상자그림에서 IQR은 제3사분위수 - 제1사분위수를 의미한다
- IQR(InterQuartile Range)로 표시하며 확률분포, 또는 자료값의 산포도를 나타내는 측도의 하나, 확률분포 또는 자료의 가운데 50%가 포함되는 범위를 "사분위수 범위"라고 한다
7. 이상치 판단에 적합하다
- Q3+1.5*IQR 보다 큰 것
- Q1-1.5*IQR 보다 작은 것
- 평균으로부터 3*표준편차 밖의 값들 => ESD 알고리즘
- 이상치로 판단된 경우 제거 여부는 해당 분야의 전문가와 상의하여 판별해야 한다
8. 상항(최댓값)과 하한(최솟값)은?
- Q1(1사분위수)= 4, Q3(3사분위수)=12
- 하한 = -8, 상한 = 22 (IQR * 1.5)
4번에서 분포 차이가 통계적으로 유의미함을 보여준다해서 틀린 것 찾기(16회)
7번에서 이상치 판단에 적합하지 않다고 해서 틀린 것 찾기 (20회)
6번에서 '사분위수 범위' 찾기 (21회)
8번 구하기 (21회)
7번 이상치 판단 방법 (22회)
7번 ESD알고리즘 주관식 문제 (22회)
7번 이상치 관련 틀린 것 찾기 (23회)
- 이상치를 판단하고 제거한다해서 틀림
산포도 척도
- 변동계수는 분포의 퍼짐 정도를 비교하게 해줌
- IQR은 제3범위수 - 1사범위수를 의미함
- 평균절대편차는 - 각 측정값과 평균 사이의 거리의 평균
- 사분위수는 데이터 표본을 4개의 동일한 부분으로 나눈 값
적절하지 않을 것 찾기 (17회)
- 평균절대편차에 대한 틀린 설명이 출제됨
히스토그램
- 히스토그램은 분포의 봉우리와 산포를 확인할 수 있다
- 히스토그램에서 양쪽 끝의 고립된 막대가 특이치를 의미함
- 연속형 자료에 적합하며, 범주형 자료는 막대 그래프 사용
- 히스토그램은 표본 크기가 20전후일 때 사용, 표본 크기가 너무 작으면 각 막대에 데이터 분포를 정확하게 표시하기에 충분한 데이터 점이 포함되지 않을 수 있음
틀린 것 찾기 (17회)
- 표본 크기와 관계가 없다해서 틀림
B.R 특징, 코드 관련
R의 특징
- R은 다양한 플랫폼을 지원한다
- R은 S 언어 기반의 프로그래밍 언어이다
- 다양한 형태의 데이터 구조를 지원한다
- 무료 소프트웨어이면서 복잡한 통계분석 기법이 가능하다
특징으로 옳지 않은 것 찾기 (23회)
데이터 타입
- 데이터 프레임 :각 열이 서로 다른 타입의 데이터 구조가 가능한 것
- 벡터
- 행렬
- 스칼라
- 리스트 : 타입이 다른 데이터 타입을 하나의 객체로 묶는 구조
각 열이 서로 다른 타입의 데이터 구조로 데이터 프레임 찾기(18회)
리스트 찾기 (20회)
R의 벡터
1. R에서 벡터는 하나 또는 하나 이상의 스칼라 원소들을 갖는 집합이다
2. 합치는 벡터에 문자형 벡터가 포함되면 합쳐지는 벡터는 문자형 벡터형을 갖는다
3. 논리연산자 벡터를 숫자형 벡터처럼 사용하는 경우 자동적으로 TRUE는 1값을 갖는다
4. R은 대소문자를 구분한다
5. dist변수의 벡터를 추출하기 위해서는 cars$dist를 실행 한다
6. 벡터의 곱셈 : y=c(1, 2, 3,NA)일 때 3*y = 3, 6, 9, NA 이다
옳은 벡터 설명 찾기, 1번만 옳은 설명으로 나옴 (16회)
2번에 대한 내용 (22회)
matrix 설명에서 as.vector(mx) 는 1행부터라고해서 틀림 (18회)
R 데이터의 형 변환
- mx <- matrix( c(23,41,12,35,67,1, 24, 7,53), nrow=3)
- as.vector(mx) 적용시 데이터는 1열부터 차례로 생성됨
- as.integer(3.14)의 값은 3
- as.numeric(FALSE)의 값은 0
- as.logical(0.45)의 값은 TRUE
summary 함수는?
- summary : 최소값, 1사분위수, 중위수, 3사분위수, 최대값, 평균값을 구할 수 있는 함수
- Min, 1st Qu. Median, Mean, 3rd Qu, Max
summary : 최소값, 1사분위수, 중위수, 3사분위수, 최대값, 평균값을 구할 수 있는 함수 (16회)
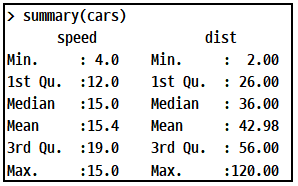
표를 보고 설명 적절하지 않은 것 찾기 (17회, 19회)
- 17회 범주형 데이터 타입이라고 해서 틀림 (범주형은 범주 : 범주당 개수로 나옴)
- 19회 speed의 제 3사분위수 알수 없다했는데... 나와 있어서 틀림
그림 보고 설명이 틀린 것 찾기 (17회)
R의 패키지 & 함수
- plyr : apply 함수와 multi-core 사용 함수를 이용하면 for loop를 사용하지 않고 매우 간단하게 처리할 수 있고, apply 함수에 기반해 데이터와 출력변수를 동시에 배열로 치환하여 처리하는 패키지
- ldply 함수 : plyr 함수 중 입력데이터는 리스트이고, 출력 데이터 형태는 데이터 프레임인 함수
plyr 묻는 객관식 문항 (20회)
R 패키지 -1
- data.table에서 dataframe으로 변경되면 ddply를 사용할 수 있다
- data.table은 데이터프레임과 유사하지만 보다 빠른 grouping이 가능함
- ply() 함수는 앞에 두 개의 문자를 접두사로 가지는데, 첫 번째 문자는 입력하는 데이터 형태를 나타내고, 두 번째 문자는 출력하는 데이터 형태를 나타낸다
- reshape 패키지의 주요 기능은 melt()와 cast()가 있다
틀린 설명 찾기 (18회)
- data.table에서 리스트로 변경되는 ddply를 사용이라해서 틀림
R의 패키지 설치 및 로드
```
install.package("패키지명), library("패키지명")
install.package("패키지명), library(패키지명)
```
알맞은 것 찾기 (답이 2개였음) (19회)
R 코딩의 결과
x <- 1:5
y <-seq(10,50,10,)
결과 <- rbind(x, y)
- 2 * 5 행렬
- 결과 [1,] 은 x와 같다
- 데이터 프레임 타입의 자료구조
(20회)
DF <-c("Monday", "Tuesday", "Wednesday")
substr(DF, 1, 2)
Out : "Mo", "Tu", "We"
(20회)
x<-c(1, 2, 3, 4)
y<-c("apple", "banana", "orange")
xy<-c(x,y)
- xy는 문자형이다
- 결과값은 "1", "2", "3", "4", "apple", "banana", "orange"
- xy[1] + xy[2]의 결과는 "12" 이다
- xy[c(5,7)], y[c(1,3)]의 결과값은 서로 같다
"apple", "banana", "orange"
(20회)
fruit <- c(5, 10, 1, 2)
names(fruit) <- c("orange", "banana", "apple", "peach")
다음은 모두 같은 결과이다
fruit[c("apple", "banana")]
fruit[3:2]
fruit[c(3,2)]
(22회)
m <- matrix(c(1,2,3,4,5,6), ncol=2, byrow=TRUE)
m
m[1,]
OUT :
1 2
(23회)
"2013-08-13" 을 문자열로 변환하는 R 코딩 방법
as.Date("08/13/2013", "%m/%d/%Y")