모형 붕괴
- 모형에서 생성한 데이터를 다시 모형에 입력
- 원래 데이터의 분포와 다른 분포로 수렴(+분산의 감소)
- 원인 :
생성된 데이터의 크기가 유한하여 확률이 낮은 사례가 누락
모형이 표현하지 못하는 정보가 상실
학습 과정에서 오류

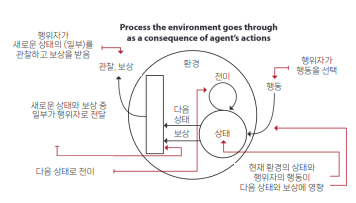
강화학습(Reinforcement Learning)
- 행위자는 환경과 상호작용
- 행위자의 행동에 따라 보상이 주어짐
- 행위자는 현재 상태에서 앞으로 수익이 가장 큰 행동을 내는 정책을 찾아야함
강화학습 예시
- 게임 인공지능 : 게임 환경에서 스스로 학습하여 최적의 전략을 수행
- 로봇 제어 : 로봇이 다양한 환경에서 최적의 행동을 학습
- 자율 주행 : 자율 주행 차량이 주행 상황에 맞춰 최적의 경로를 선택
지도 학습과 강화학습의 차이
1) 지도학습
- X에서 Y를 예측하는 문제
- X와 Y가 모두 있는 데이터가 필요
- Y에 대한 예측 오차를 줄이는 것이 목표
ex. 이메일 내용 → 스팸 여부
2) 강화학습
- 데이터 대신 직접 시행 착오
- 행동으로 인한 보상을 최대화하는 것이 목표
- 바둑) 현재 상황에서 다음 수를 시행착오를 통해 학습
- 투자) 기업의 정보에서 매수/매도/보유를 시행착오를 통해 학습
- AI가 알잘딱으로 해줌
- 굉장히 많은 시행착오가 필요(물리적 시행이 어려움)
알파고(바둑), ChatGPT(언어), 물리적 환경이 필요한 경우 시뮬레이션으로 대체
- 보상/처벌을 어떻게 줄까?
행위자와 환경
강화학습을 구성하는 두개의 주요 구성요소
1) 행위자(agent)
- 결정을 내리는 주체
- 문제에 대한 답을 제공
- 행동을 통해서 환경에 영향
2) 환경(environment)
- 문제를 대표
- 행위자의 행동에 반응
행위자와 환경의 예시
1) 주식투자
- 행위자 : 투자자
- 환경 : 주식 시장, 다른 투자자, 정치경제적 조건 등
- 행동 : 매수, 매도 보유 등
2) 운전
- 행위자 : 운전자
- 환경 : 도로, 날씨, 다른 운전자, 교통 상황 등
- 행동 : 전진, 후진, 좌회전, 우회전, 유턴, 가속, 감속 등
행위자
- 상호작용을 통해 데이터를 수집
- 현재 취하고 있는 행동을 평가
- 성능을 개선
행위자의 학습의 특성
- 시행착오를 통해 학습
- 보상 피드백의 특성
1) 순차적(sequential) : 자료가 한방에 주어지지 않음 + 행동에 대한 보상이 여러 스텝 뒤에 나타날 수 있음
2) 평가적(evaluative) : 좋은 행동인지는 알 수 있으나, 옳은 행동인지는 알 수 없음(지도 학습에는 정답이 제공됨)
3) 표본 추출된(sampled) : 모든 상태와 행동을 다 해볼 수는 없음. 그 부분 집합인 표본만 접근 가능
환경
- 행위자를 둘러싼 모든 것
- 문제와 관련된 변수들의 집합을 가짐
- 상태 공간(state space): 변수들의 모든 값의 조합
- 관찰: 행위자가 특정 시점에 얻을 수 있는 변수들의 집합
- 관찰 공간: 관찰할 수 있는 변수들의 모든 값의 조합
- 행동 공간: 행위자가 취할 수 있는 모든 상태의 집합
gymnasium(gym)
gym : 오픈AI가 개발한 강화학습 환경을 위한 라이브러리
# gymnasium 설치 a.k.a. gym
# !pip install gymnasium
할인(discounting)
동일한 보상이라도 나중에 받는 것보다 먼저 받는 것이 나음
할인율(discount factor) : 한 스텝마다 할인하는 비율
수익을 계산할 때도 할인을 적용
긴급성
할인은 긴급성에 대한 정보를 제공
할인을 적게할 경우(감마가 클 경우) : 현재와 미래의 보상에 큰 차이가 없음 → 언제 해도 상관없음
할인을 많이 할 경우(감마가 작을 경우) : 현재와 미래의 보상의 차이가 큼 → 보상을 빨리 얻는 것이 유리
보상을 빨리 받는쪽을 선호하게 하려면 할인률을 많이하면 (할인률을 낮추는 것)된다.
수익(return)

가치(value)
기대하는 수익(=여러번의 수익의 평균)
- 상태 가치: 현재 상태의 가치(앞으로 펼쳐질 모든 미래의 수익의 평균)
- 행동가치: 현재 상태에서 내가 특정 행동을 할 때 가치
- 상태 가치 = 정책(행동별 확률) * 행동가치
보상(reward)
action에 바로 직접 따라오는 것(매 step마다)
이득(advantage)
행동가치 - 상태가치
'AI > 강화학습(RL)' 카테고리의 다른 글
| [RL] 가치 기반 강화학습 (NFQ, DQN, 이중 DQN, DQNPolicy, 듀얼링) (7) | 2024.09.05 |
|---|---|
| pytorch 설치 안되는 경우 (0) | 2024.09.04 |
| 강화학습, 딥러닝 사이트 추천 (0) | 2024.09.04 |
| [RL] 시간차 학습, 동적계획법 (0) | 2024.09.04 |
| [RL] MAB, Epsilon, 낙관적 초기화 (3) | 2024.09.03 |


댓글